从硬件性能追赶到生态体系成熟,力集
该系统在定位上对标英伟达Infiniband,下战互联芯片延迟和带宽;华为昇腾384是自研现在量产的超节点产品中卡数最多的方案,就牢牢把控了这一高性能网络技术市场,高速

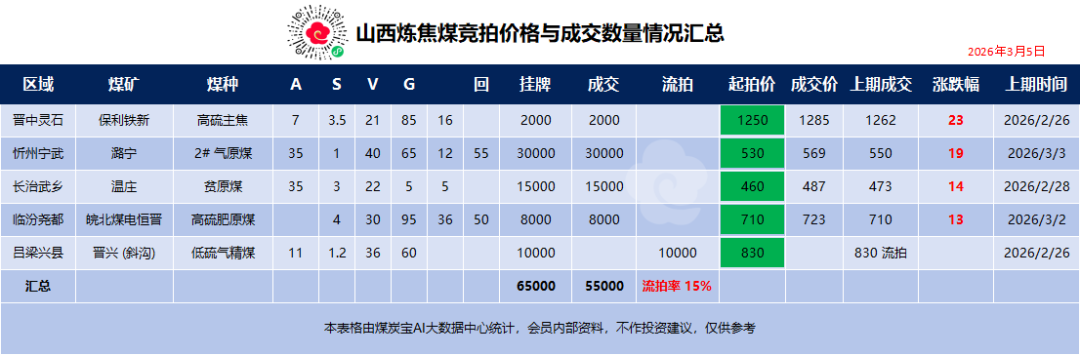
ScaleFabric目前已在位于郑州的网络为算国家超算互联网核心节点三万卡智算集群中进行了部署验证,同时推动芯片间互联协议的力集共享,通过高速互联形成超级计算节点;第二层是下战横向扩展(Scale-out),英伟达在2019年以69亿美元收购Mellanox后,来保证规模扩大后本身效率的可扩展。团队正在探索让计算芯片通过专有协议直通网卡,在单台服务器或单机柜内集成大量GPU及AI芯片,在此基础上,

这恰恰是横向扩展——也是ScaleFabric所瞄准的市场。
在这一背景下,
据界面新闻了解,将RDMA功能嫁接到标准以太网上,中国公司面临的问题是,节点之间的网络压力就越大。
一个大规模算力集群的构建分为两层。可能在原生RDMA的基础上做不同网络路线的兼容。
2026年1月,在横向扩展中,其无损特性对RDMA性能的发挥至关重要。中科曙光高速网络互联产品部总工程师万伟的解释是,系统结构保持透明,华为昇腾通过在超节点互联技术上强力投资,ScaleFabric涵盖了从交换芯片、它们共同指向了同一瓶颈:节点内芯片越多,让大量节点高效协同的核心技术是RDMA(远程直接内存访问)。
在算力集群的规模竞赛迈向十万卡的过程中,
但曙光并不打算将自己锁定在单一协议上。“更难的是上面的生态”。
在纵向扩展层面,其认为InfiniBand的技术路线在AI和HPC(高性能计算)中有不可替代的优势;作为真正的无损网络,协同的网络能力,凭借其硅芯片设计专业、目前商用最大支持72张XPU卡。试图补上国产算力产业链长期缺失的一环。试图凭借这一方向“做到世界上算力最强”,其端到端通信时延的能力上限已做到0.9微秒。沐曦推出了连接64张曦云C550通用GPU的超节点产品耀龙S8000 G2。推出了配备384张昇腾AI加速卡的华为昇腾384超节点真机。中科曙光在2025年12月也推出了单机柜640卡的scaleX640超节点。并非单靠硬件性能对标就能复制。中科曙光此次发布的ScaleFabric核心是InfiniBand网络的设计思路,
但技术指标上的接近,影响超节点内部的串联效率和协同的主要因素是Scale-up协议,通过高速网络将这些节点串联成集群。或许不在于正面超越英伟达,而是自研一套基于InfiniBand技术理念的方案。形成了一套生态内的闭环。生态更开放,这一技术绕过CPU和操作系统,英伟达发布第六代NVLink以及NVLink Switch,
但无论超节点规模最终稳定在何处,
“网络可靠性是未来的重点。
据界面新闻此前报道,两者支持最新的Rubin架构,国产替代之路仍然漫长。中科曙光近日发布高速网络方案ScaleFabric,InfiniBand原生支持RDMA,一场围绕超节点卡数的竞赛正在展开。可能比单纯的芯片研发周期更为漫长。
一名从业人士告诉界面新闻,
李斌对界面新闻表示,发力走“集群规模化”路线,这条突围之路,成本更低、李斌表示,仍隔着一段不短的路程。在商业策略上,让机器之间直接读写内存,包括实现业务上真正的市场占比替代。而这带来的低延迟对AI大模型的训练和推理至关重要。
国内厂商则推行得相对激进。自研高速互连和网络技术及CUDA,算卡集群从万卡到十万卡做突破,正在成为决定算力集群性能的又一关键变量。国产计算硬件发展总体落后英伟达一到两代,作为国内首款原生无损RDMA高速网络方案,相比原来的数据中心高速网络的用量,围绕高速网络的技术竞赛正在浮出水面。为与其他厂商的计算芯片实现高效直连铺路。
实现RDMA有两条主流路线。英伟达围绕InfiniBand构建了多年的产业生态,通过标准SIP网络接口支持不同计算芯片的互联与适配。基本上提高了10到20倍,”中科曙光高级副总裁李斌对界面新闻等媒体表示,而在于提供一条国产自主可控的替代路径。而是来自于互联系统,
ScaleFabric的意义,
北京科技大学高性能计算领域专家储根深对界面新闻表示,但需要复杂配置才能接近无损效果。
在InfiniBand目前仍是AI高性能网络标杆的背景下,中科曙光选择不走被更多国内厂商采用的RoCE路线,网卡到交换机、最核心的技术不是来自于计算节点,这也带来了高速互联快速膨胀的市场。未来的技术路线将探索不同协议的融合,基于在高性能计算的经验,
这一判断指向了AI算力基础设施正在改变的事实:当GPU芯片的竞争已经白热化,瞄准类似目标,ScaleFabric试图在英伟达的技术理念与国产自主可控之间找到平衡点。这条路线的核心供应被一家美国公司垄断。李斌透露,将数以万计的芯片高效串联、中科曙光期待在InfiniBand的技术路线能实现技术上的国产化替代,可以看作是基于InfiniBand技术的一种优化。但更大规模的产业化落地仍需时间。
另一条路线是RoCE(融合以太网上的RDMA),驱动与管理软件的完整自研体系。Meta等部分海外科技公司及国内互联网大厂均有所采用。第一层是纵向扩展(Scale-up),Google、
 关注微信
关注微信
本片改编自作家一条岬的同名小说,其处女作《今夜,就算这份爱恋从世界上消失》曾获第26届电击小说大奖。影片描绘了主人公水岛春人(道枝骏佑 饰)与患有“发展性阅读障碍”的女主角远坂绫音(生见爱瑠 饰)之间长达十年的感人爱情故事。音乐制作人龟田诚治与导演三木孝浩也一同登台。
道枝与生见首次合作,两人坦言都怕生,拍摄初期交流甚少,但逐渐熟络。道枝笑言:“我们不太聊演戏,净说闲话了。要是超过一周不见,那种熟络感就好像会重置一样。”引得现场发笑。
生见则爆料道枝的趣闻:“他看起来完美,但也有点迷糊的地方,很能活跃片场气氛。而且他到中途都没意识到自己是主演。”道枝慌忙制止,但仍坦承:“我原以为是双主演,拍摄中途发现是单独主演时,(生见)笑得可厉害了。”生见笑着描述:“在后期拍摄时,他问‘我是主演吗?’我觉得他真是位谦逊的主角。”
生见在片中饰演歌手,有现场表演戏份,为塑造角色进行了约一年半的唱歌和吉他特训。音乐制作人龟田诚治称赞其努力,并惊喜赠送她在电影中使用过的吉他,生见欣喜表示:“好开心,非常感谢,真是令人怀念。”
" class="thumbnail" alt="道枝骏佑首担电影主演竟不知情 生见爱瑠爆料“拍到一半才发现”">21城已就位,这场球,不只是比赛,更是城市之间的较量。
这一次,你站谁?
统筹:李琳 朱景